ScalarDB Analytics with PostgreSQL をはじめよう
このページは英語版のページが機械翻訳されたものです。英語版との間に矛盾または不一致がある場合は、英語版を正としてください。
このドキュメントでは、ScalarDB Analytics with PostgreSQL の使用を開始する方法について説明します。ScalarDB Analytics with PostgreSQL がすでにインストールされており、必要なサービスがすべて実行されていることを前提としています。そのような環境がない場合は、Docker を使用してローカル環境に ScalarDB Analytics with PostgreSQL をインストールする方法の手順に従ってください。ScalarDB Analytics with PostgreSQL は PostgreSQL 経由でクエリを実行するため、PostgreSQL にクエリを送信するための psql クライアントまたは別の PostgreSQL クライアントがすでにあることも前提としています。
ScalarDB Analytics with PostgreSQL とは
ユニバーサルトランザクションマネージャーである ScalarDB は、主にトランザクションワークロードを対象としているため、リレーショナルクエリの限られたサブセットをサポートしています。
ScalarDB Analytics with PostgreSQL は、PostgreSQL とその外部データラッパー (FDW) 拡張機能を使用して、ScalarDB の機能を拡張し、ScalarDB が管理するデータに対する分析クエリを処理します。
ScalarDB Analytics with PostgreSQL は、主に PostgreSQL と Schema Importer の2つのコンポーネントで構成されています。
PostgreSQL はサービスとして実行され、ユーザーからのクエ��リを受け入れて処理します。FDW 拡張機能は、ScalarDB が管理するバックエンドストレージからデータを読み取るために使用されます。Schema Importer は、ScalarDB データベースのスキーマを PostgreSQL にインポートするツールです。これにより、ユーザーは PostgreSQL 側のテーブル (ScalarDB 側のテーブルと同一) を表示できます。
ScalarDB データベースをセットアップする
まず、ScalarDB Analytics with PostgreSQL で分析クエリを実行するには、1つ以上の ScalarDB データベースが必要です。独自の ScalarDB データベースがある場合は、このセクションをスキップして、代わりにそのデータベースを使用できます。scalardb-samples/scalardb-analytics-postgresql-sample プロジェクトを使用する場合は、プロジェクトディレクトリで次のコマンドを実行してサンプルデータベースを設定できます。
docker compose run --rm schema-loader \
-c /etc/scalardb.properties \
--schema-file /etc/schema.json \
--coordinator \
--no-backup \
--no-scaling
このコマンドは、DynamoDB、PostgreSQL、Cassandra で設定される 複数のストレージインスタンスを設定します。次に、これらのストレージにマップされる dynamons、postgresns、cassandrans の名前空間を作成し、ScalarDB Schema Loaderを使用して dynamons.customer、postgresns.orders、cassandrans.lineitem のテーブルを作成します。
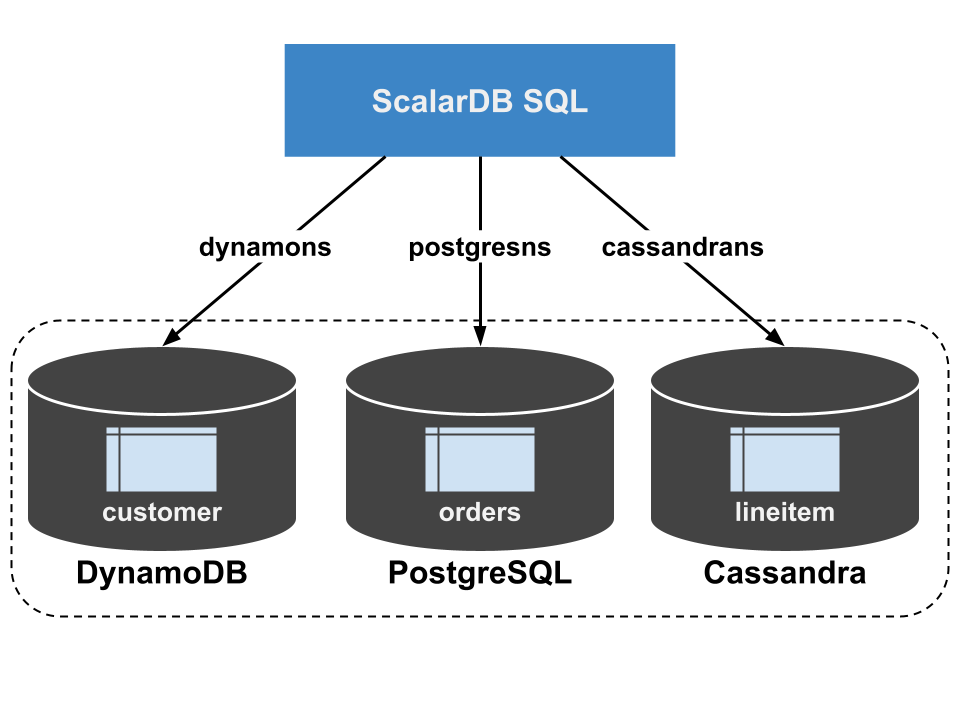
次のコマンドを実行すると、作成されたテーブルにサンプルデータをロードできます。
docker compose run --rm sample-data-loader
PostgreSQL に ScalarDB 管理下のデータベースのスキーマをインポートする
次に、分析クエリを処理する PostgreSQL に ScalarDB 管理下のデータベースのスキーマをインポートします。ScalarDB Analytics with PostgreSQL には、この目的のためのツールである Schema Importer が用意されています。このツールを使用すると、分析クエリを実行するために必要なすべての準備が整います。
docker compose run --rm schema-importer \
import \
--config /etc/scalardb.properties \
--host analytics \
--port 5432 \
--database test \
--user postgres \
--password postgres \
--namespace cassandrans \
--namespace postgresns \
--namespace dynamons \
--config-on-postgres-host /etc/scalardb.properties
独自の ScalarDB データベースを使用する場合は、--config および --config-on-postgres-host オプションを ScalarDB 設定ファイルに置き換え、--namespace オプションをインポートする ScalarDB 名前空間に置き換える必要があります。
これにより、ScalarDB データベース内のテーブルと同じ名前のテーブル (正確にはビュー) が作成されます。この例では、dynamons.customer、postgresns.orders、および cassandrans.lineitem のテーブルが作成されます。列定義も ScalarDB データベースと同一です。これらのテーブルは、FDW を使用して ScalarDB データベースの基盤となるストレージに接続された 外部テーブルです。したがって、PostgreSQL 内のこれらのテーブルを ScalarDB データベース内のテーブルと同等と見なすことができます。
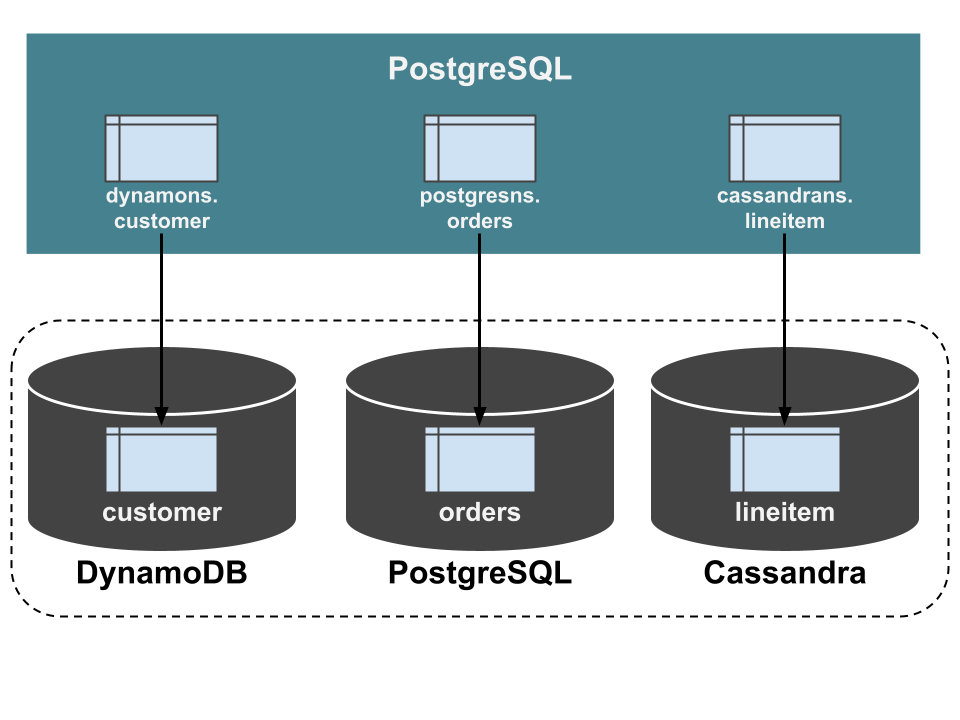
分析クエリを実行する
これで、ScalarDB データベース内の同じデータを読み取るすべてのテーブルが揃い、PostgreSQL でサポートされている任意の分析クエリを実行できるようになりました。クエリを実行するには、psql またはその他のクライアントを使用して PostgreSQL に接続してください。
psql -U postgres -h localhost test
Password for user postgres:
> select c_mktsegment, count(*) from dynamons.customer group by c_mktsegment;
c_mktsegment | count
--------------+-------
AUTOMOBILE | 4
BUILDING | 2
FURNITURE | 1
HOUSEHOLD | 2
MACHINERY | 1
(5 rows)
サンプルデータと追加の実作業の詳細については、サンプルアプリケーションページを参照してください。
注意事項
分離レベル
ScalarDB Analytics with PostgreSQL は、Read Committed 分離レベルを設定してデータを読み取ります。この分離レベルにより、読み取るデータが過去にコミットされていることが保証されますが、特定の時点で一貫性のあるデータを読み取ることができることは保証されません。
書き込み操作はサポートされていません
ScalarDB Analytics with PostgreSQL は、読み取り専用クエリのみをサポートします。INSERT、UPDATE、およびその他の書き込み操作はサポートされていません。