Java API を使用した ScalarDB Cluster の開発者ガイド
このページは英語版のページが機械翻訳されたものです。英語版との間に矛盾または不一致がある場合は、英語版を正としてください。
ScalarDB Cluster は、アプリケーションを開発するための Java API を提供します。このドキュメントでは、Java API の使用方法を説明します。
ビルドに ScalarDB Cluster Java Client SDK を追加する
ScalarDB Cluster Java Client SDK は、Maven Central Repository で入手できます。
Gradle を使用して ScalarDB Cluster Java Client SDK への依存関係を追加するには、以下を使用します。
dependencies {
implementation 'com.scalar-labs:scalardb-cluster-java-client-sdk:3.13.6'
}
Maven を使用して依存関係を追加するには、以下を使用します。
<dependency>
<groupId>com.scalar-labs</groupId>
<artifactId>scalardb-cluster-java-client-sdk</artifactId>
<version>3.13.6</version>
</dependency>
クライアントモード
ScalarDB Cluster Java Client SDK は、indirect と direct-kubernetes の2つのクライアントモードをサポートしています。以下では、クライアントモードについて説明します。
indirect クライアントモード
このモードでは、単にリクエストを任意のクラスターノードに送信します (通常は Envoy などのロードバランサー経由)。リクエストを受信したクラスターノードは、トランザクション状態を持つ適切なクラスターノードにリクエストをルーティングします。
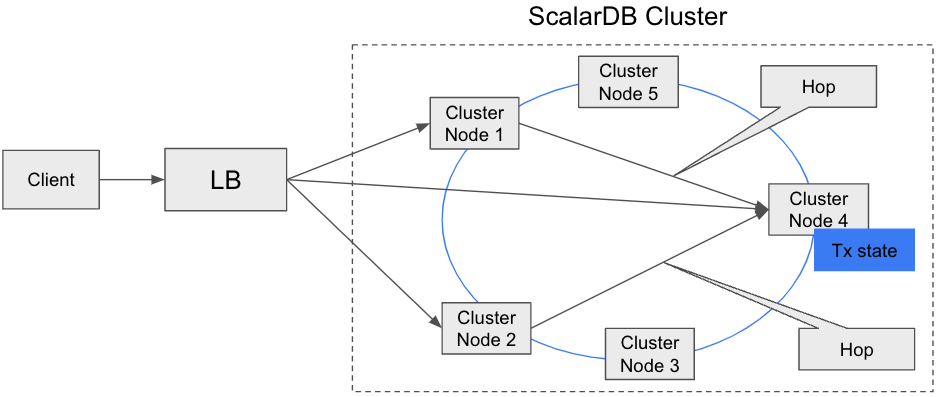
このモードの利点は、クライアントを軽量に保てることです。 欠点は、正しいクラスターノードに到達するために追加のホップが必要になり、パフォーマンスに影響する可能性があることです。
アプリケーションが別の Kubernetes クラスターで実行されていて、アプリケーションが Kubernetes API と各クラスターノードにアクセスできない場合でも、この接続モードを使用できます。
アプリケーションが ScalarDB Cluster ノードと同じ Kubernetes クラスターで実行されている場合は、direct-kubernetes クライアントモードを使用できます。
direct-kubernetes クライアントモード
このモードでは、クライアントはメンバーシップロジック (Kubernetes API を使用) と分散ロジック (コンシステントハッシュアルゴリズム) を使用して、トランザクション状態を持つ適切なクラスターノードを見つけます。次に、クライアントはクラスターノードに直接リクエストを送信します。
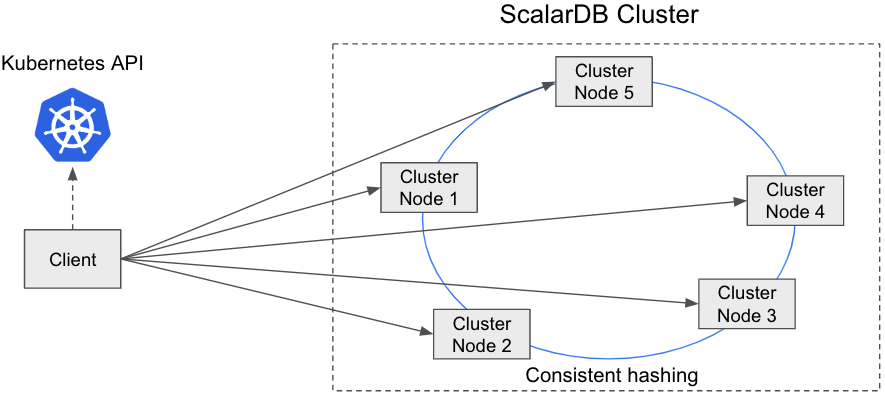
このモードの利点は、適切なクラスターノードに到達するためのホップ数を減らすことができるため、パフォーマンスが向上することです。このモードの欠点は、クライアントにメンバーシップロジックとリクエストルーティングロジックが必要なため、クライアントをファットにする必要があることです。
この接続モードは Kubernetes API と各クラスターノードにアクセスする必要があるため、アプリケーションが ScalarDB Cluster ノードと同じ Kubernetes クラスターで実行されている場合にのみ、この接続モードを使用できます。アプリケーションが別の Kubernetes クラスターで実行されている場合は、indirect クライアントモードを使用します。
direct-kubernetes クライアントモードで Kubernetes にアプリケーションをデプロイする方法の詳細については、direct-kubernetes モードを使用してクライアントアプリケーションを Kubernetes にデプロイする を参照し�てください。
ScalarDB Cluster Java API
ScalarDB Cluster Java Client SDK は、アプリケーションが ScalarDB Cluster にアクセスするための Java API を提供します。次の図は、ScalarDB Cluster Java API のアーキテクチャを示しています。
+-----------------------+
| ユーザー/アプリケーション |
+-----------------------+
↓ Java API
+--------------+
| ScalarDB API |
+--------------+
↓ gRPC
+------------------+
| ScalarDB Cluster |
+------------------+
↓ DB ベンダー固有のプロトコル
+----+
| DB |
+----+
ScalarDB Cluster Java API の使用は、クライアント設定と Schema Loader が異なることを除いて、ScalarDB Java API の使用とほぼ同じです。詳細については、ScalarDB Java API ガイド を参照してください。
次のセクションでは、ScalarDB Cluster Java API とクラスター用 Schema Loader のクライアント設定について説明します。
クラスター用 Schema Loader
ScalarDB Cluster 経由でスキーマをロードするには、専用の ScalarDB Cluster 用 Schema Loader (クラスター用 Schema Loader) を使用する必要があります。クラスター用Schema Loader の使用方法は、JAR ファイルの名前が異なることを除いて、ScalarDB Schema Loader の使用方法と基本的に同じです。クラスター用 Schema Loader は、ScalarDB リリース からダウン��ロードできます。JAR ファイルをダウンロードしたら、次のコマンドでクラスター用 Schema Loader を実行できます。
java -jar scalardb-cluster-schema-loader-3.13.6-all.jar --config <PATH_TO_SCALARDB_PROPERTIES_FILE> --schema-file <PATH_TO_SCHEMA_FILE> --coordinator
次のコマンドを実行して、Scalar コンテナレジストリ から Docker イメージを取得することもできます。山括弧内の内容は説明に従って置き換えてください:
docker run --rm -v <PATH_TO_YOUR_LOCAL_SCALARDB_PROPERTIES_FILE>:/scalardb.properties -v <PATH_TO_YOUR_LOCAL_SCHEMA_FILE>:/schema.json ghcr.io/scalar-labs/scalardb-cluster-schema-loader:3.13.6 --config /scalardb.properties --schema-file /schema.json --coordinator
ScalarDB Cluster SQL
ScalarDB Cluster SQL には、次のように Java の ScalarDB 用 JDBC および Spring Data JDBC を介してアクセスできます。
+----------------------------------------------+
| ユーザー/アプリケーション |
+----------------------------------------------+
↓ ↓ Java API
Java API ↓ +-------------------------------+
(JDBC) ↓ | Spring Data JDBC for ScalarDB |
↓ +-------------------------------+
+----------------------------------------------+
| ScalarDB JDBC (ScalarDB SQL) |
+----------------------------------------------+
↓ gRPC
+----------------------+
| ScalarDB Cluster SQL |
+----------------------+
↓ DB ベンダー固有のプロトコル
+----+
| DB |
+----+
このセクションでは、JDBC 経由で ScalarDB Cluster SQL を使用する方法と、Spring Data JDBC for ScalarDB を使用する方法について説明します。
JDBC 経由の ScalarDB Cluster SQL
JDBC 経由での ScalarDB Cluster SQL の使用は、プロジェクトに JDBC ドライバーを追加する方法を除いて、ScalarDB JDBC を使用する場合とほぼ同じです。
ビルドに ScalarDB Cluster Java Client SDK を追加する で説明されているように ScalarDB Cluster Java Client SDK を追加することに加えて、プロジェクトに次の�依存関係を追加する必要があります。
Gradle を使用して ScalarDB Cluster JDBC ドライバーへの依存関係を追加するには、以下を使用します。
dependencies {
implementation 'com.scalar-labs:scalardb-sql-jdbc:3.13.6'
implementation 'com.scalar-labs:scalardb-cluster-java-client-sdk:3.13.6'
}
Maven を使用して依存関係を追加するには、以下を使用します。
<dependencies>
<dependency>
<groupId>com.scalar-labs</groupId>
<artifactId>scalardb-sql-jdbc</artifactId>
<version>3.13.6</version>
</dependency>
<dependency>
<groupId>com.scalar-labs</groupId>
<artifactId>scalardb-cluster-java-client-sdk</artifactId>
<version>3.13.6</version>
</dependency>
</dependencies>
それ以外は、JDBC 経由で ScalarDB Cluster SQL を使用することは、ScalarDB JDBC を使用することと同じです。ScalarDB JDBC の詳細については、ScalarDB JDBC ガイド を参照してください。
Spring Data JDBC for ScalarDB 経由の ScalarDB Cluster SQL
JDBC 経由の ScalarDB Cluster SQL と同様に、Spring Data JDBC for ScalarDB 経由の ScalarDB Cluster SQL を使用することは、プロジェクトへの追加方法を除いて、Spring Data JDBC for ScalarDB を使用することとほぼ同じです。
ScalarDB Cluster Java Client SDK をビルドに追加する で説明されているように ScalarDB Cluster Java Client SDK を追加することに加えて、プロジェクトに次の依存関係を追加する必要があります:
Gradle を使用して依存関係を追加するには、以下を使用します:
dependencies {
implementation 'com.scalar-labs:scalardb-sql-spring-data:3.13.6'
implementation 'com.scalar-labs:scalardb-cluster-java-client-sdk:3.13.6'
}
Maven を使用して依存関係を追加するには、以下を使用します。
<dependencies>
<dependency>
<groupId>com.scalar-labs</groupId>
<artifactId>scalardb-sql-spring-data</artifactId>
<version>3.13.6</version>
</dependency>
<dependency>
<groupId>com.scalar-labs</groupId>
<artifactId>scalardb-cluster-java-client-sdk</artifactId>
<version>3.13.6</version>
</dependency>
</dependencies>
それ以外では、Spring Data JDBC for ScalarDB 経由で ScalarDB Cluster SQL を使用することは、Spring Data JDBC for ScalarDB を使用することと同じです。Spring Data JDBC for ScalarDB の詳細については、Spring Data JDBC for ScalarDB ガイド を参照してください。
SQL CLI
他の SQL データベースと同様に、ScalarDB SQL にも、コマンドラインシェルで対話的に SQL ステートメントを発行できる CLI ツールが用意されています。
Cluster 用の SQL CLI は、ScalarDB リリース からダウンロードできます。JAR ファイルをダウンロードしたら、次のコマンドで SQL CLI を実行できます。
java -jar scalardb-cluster-sql-cli-3.13.6-all.jar --config <PATH_TO_SCALARDB_SQL_PROPERTIES_FILE>
次のコマンドを実行して、Scalar コンテナレジストリ から Docker イメージを取得することもできます。山括弧内の内容は説明に従って置き換えてください:
docker run --rm -it -v <PATH_TO_YOUR_LOCAL_SCALARDB_SQL_PROPERTIES_FILE>:/scalardb-sql.properties ghcr.io/scalar-labs/scalardb-cluster-sql-cli:3.13.6 --config /scalardb-sql.properties
使用方法
CLI の使用方法は、次のように -h オプションを使用して確認できます。
java -jar scalardb-cluster-sql-cli-3.13.6-all.jar -h
Usage: scalardb-sql-cli [-hs] -c=PROPERTIES_FILE [-e=COMMAND] [-f=FILE]
[-l=LOG_FILE] [-o=<outputFormat>] [-p=PASSWORD]
[-u=USERNAME]
Starts ScalarDB SQL CLI.
-c, --config=PROPERTIES_FILE
A configuration file in properties format.
-e, --execute=COMMAND A command to execute.
-f, --file=FILE A script file to execute.
-h, --help Display this help message.
-l, --log=LOG_FILE A file to write output.
-o, --output-format=<outputFormat>
Format mode for result display. You can specify
table/vertical/csv/tsv/xmlattrs/xmlelements/json/a
nsiconsole.
-p, --password=PASSWORD A password to connect.
-s, --silent Reduce the amount of informational messages
displayed.
-u, --username=USERNAME A username to connect.
参考資料
Java 以外のプログラミング言語で ScalarDB Cluster を使用する場合は、ScalarDB Cluster gRPC API を使用できます。 ScalarDB Cluster gRPC API の詳細については、以下を参照してください。
Javadocs も利用可能です: